Note: I originally published this on the zillablog:

Kanye West and Jay-Z, Dr. Dre and Snoop Dogg, Raekwon and Ghostface Killah, Lil Wayne and Drake: some rappers are best known for their featured appearances and partnerships. After countless debates over the greatest rap duo of all time (still Raekwon and Ghostface, for the record), I was curious about how easily I could quantify the strength of rap affiliations. I also wanted to find out how interconnected the network of rap collaborations really was.
Who collaborates the most with other artists? Which pairs of artists have the most collaborations? And, most importantly, if we modeled the entire network of hip hop artists as an undirected graph, how would Lil Wayne’s PageRank stack up to Kanye West or RZA? These are fascinating questions. Somebody, somewhere woke up today wondering all of these things.
Modeling the Data
In the “Hip Hop Graph,” artists (producers are considered artists) are represented as nodes, and edges between nodes represent collaborations between artists. It is straightforward to represent edge weights between two artists as the number of collaborations in the corpus of songs. For ease of use in calculations (i.e. shortest paths and minimum spanning trees), taking the inverse of the number of collaborations (1 / # collaborations) is a common technique. The graphs displayed consist of the connections of the 130 most prolific artists.
The final result (one layout of the minimum spanning tree) using networkx (the python package) and Gephi:
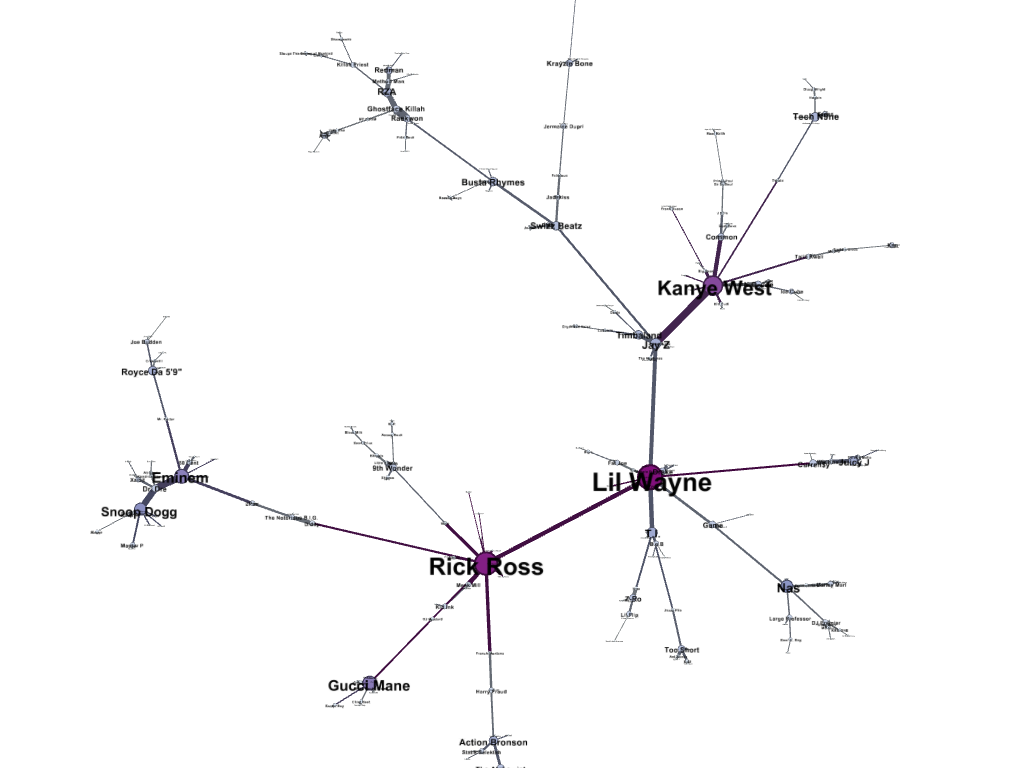
Another image of the minimum spanning tree, zoomed in. The size and color of the nodes is correlated with the degree of the node in the MST.
I chose to model the Hip Hop Graph as an undirected graph, in which one collaboration consists of any song in which both artists are featured (either as primary artist, featured artists, or producer). For example, the song “Winter Warz” by Ghostface Killah, featuring Cappadonna, Masta Killa, Raekwon, and U-God, produced by RZA has {6 C 2} = 12 combinations of collaborations.
For any song, there are three categories of artists. Each song has a “primary artist” to whom the track is attributed. Additionally, every song may have multiple featured artists and one or more producers. To generate the graph, I needed to produce a dataset of the specific format:
{String song, String artist, Array featuredArtists, Array producers }
Finding easily accessible music metadata that conforms to this format of attribution is not an easy task. However, certain websites such as Rap Genius maintain metadata on each song in this format. So the song corpus being analyzed is the set of songs registered for artists on Rap Genius.
I wrote a quick and dirty scraper in python for Rap Genius’ html using BeautifulSoup that served as my API. The first function returns the URLs for all the songs attributed to a particular primary artist:
from bs4 import BeautifulSoup
import requests
from urlparse import parse_qs, urlsplit
RAPGENIUS_URL = 'http://rap.genius.com'
RAPGENIUS_SEARCH_URL = 'http://genius.com/search'
RAPGENIUS_ARTIST_URL = 'http://genius.com/artists'
def getArtistSongs(url):
soup = BeautifulSoup(requests.get(url).text)
songs = []
for row in soup.findAll('ul', class_='song_list primary_list '):
try:
songs.append(row.find('a').get('href'))
continue
except:
print "couldnt find songs"
for r in soup('div', {'class':'pagination'}):
links = r.findAll('a')
try:
last = int(links[-2].string)
for i in xrange(last):
i += 4
upart = links[-2].get('href')
nurl = RAPGENIUS_URL + upart
print nurl
scheme, netloc, path, query_string, fragment = urlsplit(nurl)
query_params = parse_qs(query_string)
query_params['page'] = [str(i)]
r = requests.get(RAPGENIUS_URL + path, params=query_params)
r = r.text
page = BeautifulSoup(r)
for pageRow in page.find('ul', class_='song_list primary_list '):
if(type(pageRow.find('span'))!=int):
songs.append(pageRow.find('a').get('href'))
except:
print "error somewhere"
return songsThe second function extracts the primary artist, featured artists, and producers for any given song URL:
def setSong(url):
soup = BeautifulSoup(requests.get(url).text)
featured = []
producers = []
aName = ''
#Extract primary artist name
try:
art = soup.find('span', class_= 'text_artist')
aName = art.contents[1].text
#print aName
except:
pass
#Extract featured artist names
try:
features = soup.find('span', class_='featured_artists').contents
for f in features:
try:
featured.append(f.text)
except:
pass
except:
pass
#Extract producers' names
try:
features = soup.find('span', class_='producer_artists').contents
for f in features:
try:
producers.append(f.text)
except:
pass
except:
pass
return (aName, featured, producers)Using Zillabyte to Gather Data
In order to get all the data I needed, I had to pipe these two functions together to get all the metadata for my entire list of songs. This required a number of http requests to Rap Genius. Zillabyte allows easy distributed crawling, using pipe programming to modify streams of tuples. Here are some basic Zillabyte apps that should get you familiar with pipe programming and stream processing. Using Zillabyte, I could fetch about 30,000 songs’ data in 45 minutes with a parallelism of 8.
I seeded my app with a CSV of hip hop artists I was interested in; these are the first 10 rows:
Eminem
Outkast
JayZ
WuTangClan
UGK
Drake
Raekwon
MethodMan
2Pac
KanyeWestHere is the code for the Zillabyte app:
import zillabyte
#rapgenius.py is the module that houses the two functions above
from rapgenius import *
import csv
def prep(controller):
return
def getsongs(controller, tup):
artist = tup["artist"]
artistUrl = "http://genius.com/artists/" + artist
songs = getMostArtistSongs(artistUrl)
for song in songs:
print song
controller.emit({"song" : song, "artist" : artist})
return
def buildGraph(controller, tup):
song = tup["song"]
artist = tup["artist"]
songData = setSong(song)
print songData
controller.emit({"song" : song, "artist": songData[0], "featuredArtists": songData[1], "producers": songData[2]})
def nt(controller):
with open("rapperlist.csv") as rl:
for line in rl:
controller.emit({"artist" : line})
controller.end_cycle()
app = zillabyte.app(name = "pygenius")
app.source(name="raplist", next_tuple = nt, end_cycle_policy="explicit")\
.each(execute = getsongs)\
.each(execute = buildGraph)\
.sink(name = "zbrap", columns = [{"song":"string"}, {"artist":"string"}, {"featuredArtists":"array"}, {"producers":"array"}])This app uses the python syntax with my seeded list of artists as the custom source. Zillabyte’s pipe programming paradigm applies a series of transformations to a stream of tuples. This app uses the following workflow:
source: list of artists => each: list of urls of all available songs for every artist => each: extract artist, features, and producers metadata for each song’s url => sink: emit to CSV
An example row of the sunk CSV:
“3070”,”http://rap.genius.com/Kanye-west-mercy-lyrics”,”Kanye West”,”["2 Chainz"\,"Big Sean"\,"Pusha T"]”,”["Hudson Mohawke"\,"Kanye West"\,"Lifted"\,"Mike Dean"\,"Mike WiLL Made It"]”,”2014-10-21 19:51:36”,”1”,””
Visualization
The fully connected graph has so many strongly connected components that distinguishing between rendered edges becomes extremely difficult. An excellent and simple method to limit the number of rendered edges is to build a minimum spanning tree from the fully connected graph. Keeping my workflow in python, I used an extracting script and networkx on the output CSV to generate the graph. Check out the code on GITHUB
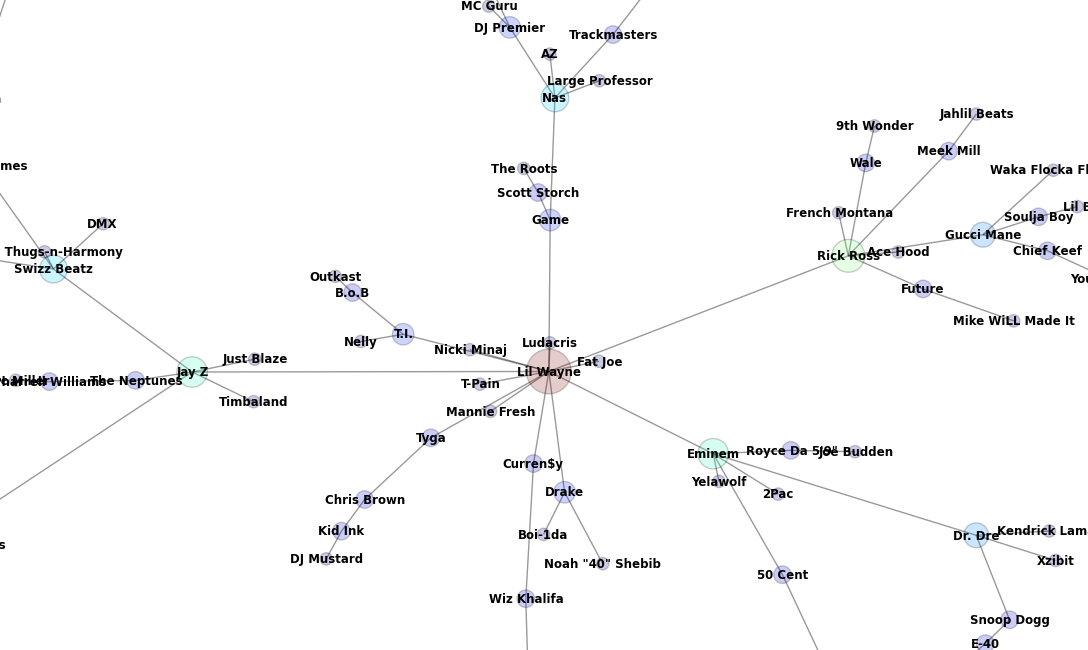
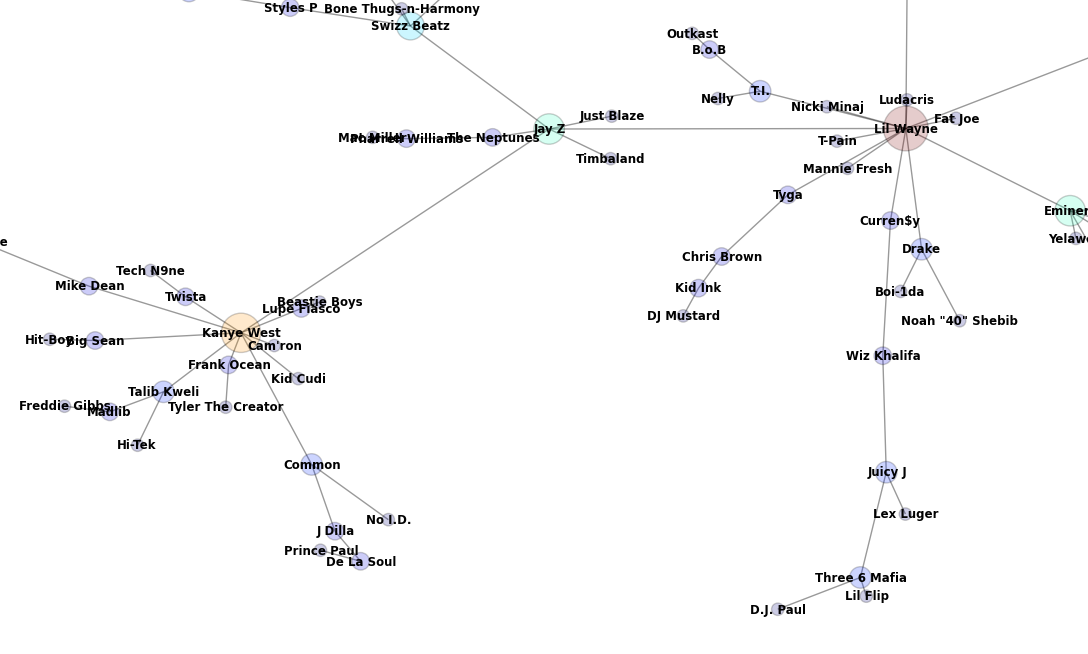
Kanye West’s quadrant of the MST:
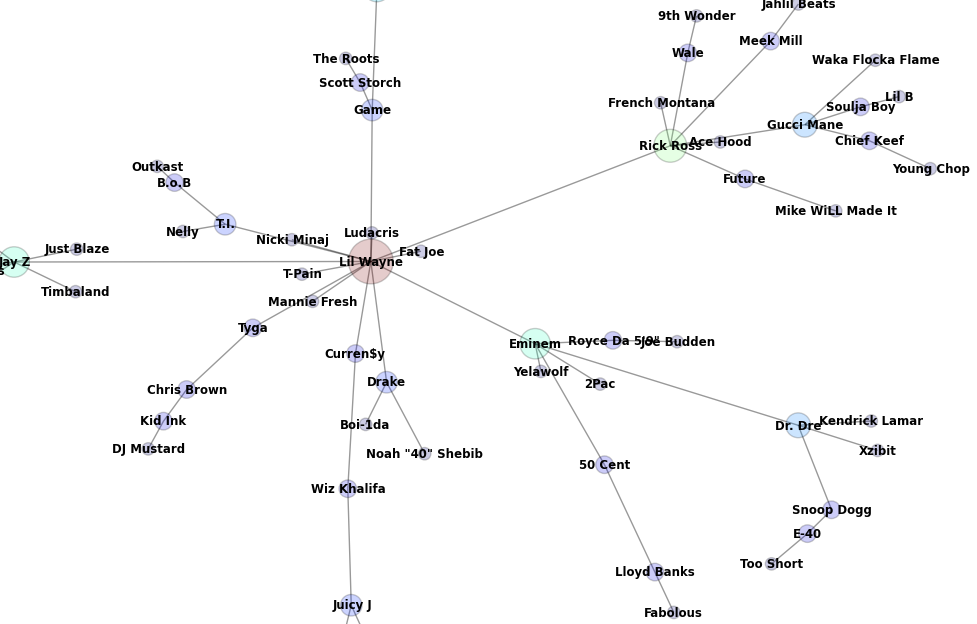
Eminem’s quadrant:
I struggled a bit generating user friendly and informative layouts for the graphs, and definitely noticed some strange connections in the graph.
Odd Surprises
Anyone familiar with the last 30 years of hip hop should be skeptical of some of the connections in this graph. For example, it should be obvious that 2Pac and Eminem never collaborated while 2Pac was alive, but they are first degree connections in the minimum spanning tree. While bizarre on face, in fact, Eminem is credited as a producer on some of 2Pac’s posthumous material. Inevitably, the quality of the results is highly dependent on the cleanliness of the input data source, in this case Rap Genius. Certainly, there are some instances of duplicated songs, but the most significant source of confusion is that some nontrivial number of songs on rap genius are from mixtape and unofficial remixes, with which many hip hop fans may be unfamiliar.
Moving towards Data Analysis…
Many of the questions I posed initially, especially the one in the title, remain to be answered. So far, I have completed much of the legwork of generating a structured graph with mostly validated data. In the next post, I will actually determine the PageRank of our favorite rappers (and Lil Wayne) in a distributed fashion using Zillabyte.